DMTCP: Distributed MultiThreaded Checkpointing¶
DMTCP is a Checkpoint/Restart (C/R) tool that can transparently checkpoint a threaded or distributed computation into disk, requiring no modifications to user codes or to the Linux kernel. It can be used by unprivileged users (no root privilege needed).
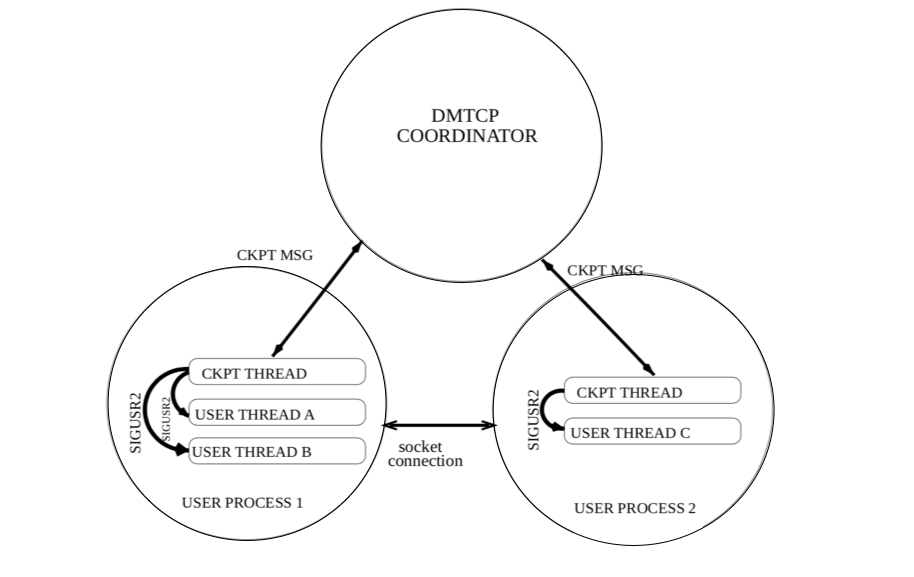
DMTCP implements a coordinated checkpointing, as shown in the figure below. There is one DMTCP coordinator for each job (computation) to checkpoint, which is started from one of the nodes allocated to the job, using the dmtcp_coordinator command. Application binaries are then started under the DMTCP control using the dmtcp_launch command, connecting them to the coordinator upon startup. For each user process, a checkpoint thread is spawned that executes commands from the coordinator (default port: 7779). Then, DMTCP starts transparent checkpointing, writing checkpoint files to the disk either periodically or as needed. The job can be restarted from the checkpoint files using the dmtcp_restart command later.
Note
- During the checkpoint and restart process, either the DMTCP checkpoint thread or the user threads are active, but never both at the same time.
- Checkpoint files are backed up, so even if the coordinator dies while checkpoint files are being written, it can be resumed from previous, successfully generated checkpoint files.
- A DMTCP checkpoint file includes the running process's memory, context, and open files as well as runtime libraries and the Linux environment variables.
DMTCP supports a variety of applications, including MPI (various implementations over TCP/IP or InfiniBand), OpenMP, MATLAB, Python, and many programming languages including C/C++/Fortran, shell scripting languages, and resource managers (e.g., Slurm). However, it does not support the Cray MPICH over Aries network on Cori. We therefore recommend users to use DMTCP for serial and threaded applications. For MPI applications, we recommend MANA, which is implemented as a plugin in DMTCP and works with any MPI implementation including Cray MPICH.
DMTCP on Cori¶
DMTCP is installed as a module on Cori. To access, do
module load dmtcp
To see what dmtcp module does, do
module show dmtcp
Output of module show dmtcp command on Cori
cori$ module show dmtcp
-------------------------------------------------------------------
/usr/common/software/modulefiles/dmtcp/2019-10-24:
module-whatis DMTCP (Distributed MultiThreaded Checkpointing) transparently checkpoints
a single-host or distributed computation in user-space -- with no modifications
to user code or to the O/S.
setenv DMTCP_DIR /global/common/sw/cray/cnl7/haswell/dmtcp/2019-10-24
setenv DMTCP_DL_PLUGIN 0
prepend-path LD_LIBRARY_PATH /global/common/sw/cray/cnl7/haswell/dmtcp/2019-10-24/lib
prepend-path PATH .
prepend-path PATH /global/common/sw/cray/cnl7/haswell/dmtcp/2019-10-24/bin
prepend-path MANPATH /global/common/sw/cray/cnl7/haswell/dmtcp/2019-10-24/share/man
-------------------------------------------------------------------
Benefits of Checkpointing/Restart¶
You are encouraged to experiment with DMTCP with your applications, enabling checkpoint/restart in your production workloads. Benefits of checkpointing and restarting jobs with DMTCP includes,
- increased job throughput
- the capability of running jobs of any length
- a 75% charging discount on Cori KNL and the 50% charging discount on Haswell when using the flex QOS
- reduced machine time loss due to system failures
Compile to Use DMTCP¶
To use DMTCP to checkpoint/restart your applications, you do not need to modify any of your codes. However, you must link your application dynamically, and build shared libraries for the libraries that your application depends on.
C/R Serial/Threaded Applications with DMTCP¶
C/R Interactive Jobs¶
You can use DMTCP to checkpoint and restart your serial/threaded application interactively, which is convenient when testing and debugging DMTCP jobs. Here are the steps on Cori:
Checkpointing¶
-
Get on a compute node using the
salloccommand, e.g., requesting 1 KNL node for one hour,salloc –N1 –C knl –t 1:00:00 -q interactiveload the dmtcp module once on the compute node.
module load dmtcp -
Open another terminal, and ssh to the compute node that is allocated for your job -- instructions here. Then start the DMTCP coordinator.
module load dmtcp dmtcp_coordinator -
On the first terminal (batch session), launch your application (
a.out) with thedmtcp_launchcommand.dmtcp_launch ./a.out [arg1 ...] -
While your job is running, on the second terminal (where the coordinator is running), you can send a checkpoint and other commands to your running job. Type '?' for available commands. E.g., 'c' for checkpointing, 's' for querying the job status, and 'q' for terminating the job,
c s q
Restarting¶
Repeat steps 1-2 and 4 above, and replace step 3 with the dmtcp_restart command. Here are the steps on Cori:
-
Get on a compute node - same as step 1 above
-
Start the coordinator on another terminal - same as step 2 above
-
Restart application from checkpoint files using
dmtcp_restartcommanddmtcp_restart ckpt_a.out_*.dmtcp -
Send checkpoint and other commands from the coordinator prompt - same as step 4 above
In the example above, the dmtcp_coordinator command is invoked before the application launch. If not, both dmtcp_launch and dmtcp_restart invoke dmtcp_coordinator internally, which then detaches from its parent process. You can also run dmtcp_coordinator as a daemon (using the --daemon option) in the background (this is useful for batch jobs). DMTCP provides a command, dmtcp_command, to send the commands to the coordinator remotely.
dmtcp_command --checkpoint # checkpoint all processes
dmtcp_command --status # query the status
dmtcp_command --quit # kill all processes and quit
All dmtcp_* commands support command line options (use --help to see the list). For instance, you can enable periodic checkpointing using the -i <checkpoint interval (secs)> option when invoking the dmtcp_coordinator, dmtcp_launch or dmtcp_restart command. Both dmtcp_launch and dmtcp_restart assume the coordinator is running on the localhost and listening to the port number 7779. If the coordinator runs at different host and listens to a different port, you can use the -h <hostname> and -p <port number> options or using the environment variables, DMTCP_COORD_HOST and DMTCP_COORD_PORT, to make dmtcp_launch or dmtcp_restart connect to their coordinator.
C/R Batch Jobs¶
Assume the job you wish to checkpoint is run.slurm as shown below, in which you request a Cori node to run an OpenMP application for 48 hours. You can checkpoint and restart this job using the C/R job scripts below, run_launch.slurm and run_restart.slurm.
Cori Haswell¶
run.slurm: the job you wish to checkpoint
#!/bin/bash
#SBATCH -J test
#SBATCH -q regular
#SBATCH -N 1
#SBATCH -C haswell
#SBATCH -t 48:00:00
#SBATCH -o %x-%j.out
#SBATCH -e %x-%j.err
#user setting
export OMP_PROC_BIND=true
export OMP_PLACES=threads
export OMP_NUM_THREADS=32
./a.out
run_launch.slurm: launches your job under DMTCP control
#!/bin/bash
#SBATCH -J test_cr
#SBATCH -q regular
#SBATCH -N 1
#SBATCH -C haswell
#SBATCH -t 48:00:00
#SBATCH -o %x-%j.out
#SBATCH -e %x-%j.err
#SBATCH --time-min=6:00:00
#user settings
export OMP_PROC_BIND=true
export OMP_PLACES=threads
export OMP_NUM_THREADS=32
#for c/r with dmtcp
module load dmtcp nersc_cr
#checkpointing once every hour
start_coordinator -i 3600
#running under dmtcp control
dmtcp_launch -j ./a.out
run_restart.slurm: restarts your job from checkpoint files with DMTCP
#!/bin/bash
#SBATCH -J test_cr
#SBATCH -q regular
#SBATCH -N 1
#SBATCH -C haswell
#SBATCH -t 48:00:00
#SBATCH -o %x-%j.out
#SBATCH -e %x-%j.err
#SBATCH --time-min=6:00:00
#for c/r with dmtcp
module load dmtcp nersc_cr
#checkpointing once every hour
start_coordinator -i 3600
#restarting from dmtcp checkpoint files
./dmtcp_restart_script.sh
Cori KNL¶
run.slurm: the job you wish to checkpoint
#!/bin/bash
#SBATCH -J test
#SBATCH -q regular
#SBATCH -N 1
#SBATCH -C knl
#SBATCH -t 48:00:00
#SBATCH -o %x-%j.out
#SBATCH -e %x-%j.err
#user setting
export OMP_PROC_BIND=true
export OMP_PLACES=threads
export OMP_NUM_THREADS=64
./a.out
run_launch.slurm: launches your job under DMTCP control
#!/bin/bash
#SBATCH -J test_cr
#SBATCH -q flex
#SBATCH -N 1
#SBATCH -C knl
#SBATCH -t 48:00:00
#SBATCH -o %x-%j.out
#SBATCH -e %x-%j.err
#SBATCH --time-min=2:00:00
#user setting
export OMP_PROC_BIND=true
export OMP_PLACES=threads
export OMP_NUM_THREADS=64
#to c/r with dmtcp
module load dmtcp nersc_cr
#checkpointing once every hour
start_coordinator -i 3600
#running under dmtcp control
dmtcp_launch -j ./a.out
run_restart.slurm: restarts your job from checkpoint files with DMTCP
#!/bin/bash
#SBATCH -J test_cr
#SBATCH -q flex
#SBATCH -N 1
#SBATCH -C knl
#SBATCH -t 48:00:00
#SBATCH -o %x-%j.out
#SBATCH -e %x-%j.err
#SBATCH --time-min=2:00:00
#for c/r with dmtcp
module load dmtcp nersc_cr
#checkpointing once every hour
start_coordinator -i 3600
#restarting from dmtcp checkpoint files
./dmtcp_restart_script.sh
Since now you can checkpoint and restart the job with DMTCP, you can run your long job (48 hours) in multiple shorter ones. This increases your job's backfill opportunities, thereby improving your job throughput. You can use the --time-min sbatch flag to specify a minimum time limit (6 hours in the Haswell example) for your C/R job, allowing your job to run with any time limit between 6 to 48 hours. Note that you must use --time-min=2:00:00 or less to get the 75% charging discount on KNL and the 50% charging discount on Haswell from using the flex QOS.
In the C/R job scripts, in addition to loading the dmtcp module, the nersc_cr module is loaded as well, which provides a set of bash functions to manage C/R jobs. For example, start_coordinator is a bash function that invokes the dmtcp_coordinator command as a daemon in the background, and assigns an arbitrary port number for the coordinator.
dmtcp_coordinator --daemon --exit-on-last -p 0 --port-file $fname $@ 1>/dev/null 2>&1
In addition, it saves the coordinator's host and port number into the environment variables, DMTCP_COORD_HOST and DMTCP_COORD_PORT, and generates a wrapped dmtcp_command for your job, dmtcp_command.<jobid>, in your run directory for you to communicate with your running job later. You can pass the dmtcp_coordinator command line option to the start_coordinator. The C/R jobs above checkpoint once every hour (-i 3600).
The dmtcp_restart_script.sh used in the restart job scripts is a bash script generated by the dmtcp_coordinator. It wraps the dmtcp_restart command to use the most recent successful checkpoint files for your convenience. Of course, you can invoke dmtcp_restart directly by providing the checkpoint files on the command line (as in the interactive example above).
To run the job, just submit the C/R job scripts above,
sbatch run_launch.slurm
sbatch run_restart.slurm #if the first job is pre-terminated
sbatch run_restart.slurm #if the second job is pre-terminated
...
The first job will run with a time limit anywhere between the specified time-min and 48 hours. If it is pre-terminated, then you need to submit the restart job, run_restart.slurm. You may need to submit it multiple times until the job completes or has run for 48 hours as requested. You can use the job dependencies to submit all your C/R jobs at once (you may need to submit many more restart jobs than needed). You can also combine the two C/R job scripts into one (see the next section), and then submit it multiple times as dependent jobs all at once. However, this is still not as convenient as submitting the job script run.slurm only once. The good news is that you can automate the C/R jobs using the features supported in Slurm and a trap function (see the next section). The job scripts in the next section are recommended to run C/R jobs.
Note
While your C/R job is running, you can checkpoint your job remotely (manually), if needed, using the wrapped dmtcp_command command, dmtcp_command.<jobid>, which is available on your job's run directory. You can run this command from a Cori login node as follows:
module load dmtcp
mom_local.py dmtcp_command.<jobid> --checkpoint
Where the mom_local.py script transfers your environment and the dmtcp_command.<jobid> command to a Cori mom node and executes the command there. You need to do this because the direct socket operations (used by DMTCP) from external login nodes to compute nodes is not supported on Cori. Alternatively, you can execute the following command from your job's head compute node (by following the instructions here ):
module load dmtcp
dmtcp_command.<jobid> --checkpoint
Automate C/R Jobs¶
C/R job submissions can be automated using the variable-time job script, so that you just need to submit a single job script once as you would with your original job script, run.slurm.
Here are the sample job scripts:
Cori Haswell¶
run_cr.slurm: a sample job script to checkpoint and restart your job with DMTCP automatically
#!/bin/bash
#SBATCH -J test
#SBATCH -q flex
#SBATCH -N 1
#SBATCH -C haswell
#SBATCH -t 48:00:00
#SBATCH -e %x-%j.err
#SBATCH -o %x-%j.out
#SBATCH --time-min=02:00:00
#
#SBATCH --comment=48:00:00
#SBATCH --signal=B:USR1@300
#SBATCH --requeue
#SBATCH --open-mode=append
#for c/r jobs
module load dmtcp nersc_cr
#checkpointing once every hour
start_coordinator -i 3600
#c/r jobs
if [[ $(restart_count) == 0 ]]; then
#user setting
export OMP_PROC_BIND=true
export OMP_PLACES=threads
export OMP_NUM_THREADS=32
dmtcp_launch -j ./a.out &
elif [[ $(restart_count) > 0 ]] && [[ -e dmtcp_restart_script.sh ]]; then
./dmtcp_restart_script.sh &
else
echo "Failed to restart the job, exit"; exit
fi
# requeueing the job if remaining time >0
ckpt_command=ckpt_dmtcp #additional checkpointing right before the job hits the walllimit
requeue_job func_trap USR1
wait
Cori KNL¶
run_cr.slurm: a sample job script to checkpoint and restart your job with DMTCP automatically
#!/bin/bash
#SBATCH -J test
#SBATCH -q flex
#SBATCH -N 1
#SBATCH -C knl
#SBATCH -t 48:00:00
#SBATCH -e %x-%j.err
#SBATCH -o %x-%j.out
#SBATCH --time-min=02:00:00
#
#SBATCH --comment=48:00:00
#SBATCH --signal=B:USR1@300
#SBATCH --requeue
#SBATCH --open-mode=append
module load dmtcp nersc_cr
#checkpointing once every hour
start_coordinator -i 3600
#c/r jobs
if [[ $(restart_count) == 0 ]]; then
#user setting
export OMP_PROC_BIND=true
export OMP_PLACES=threads
export OMP_NUM_THREADS=64
dmtcp_launch -j ./a.out &
elif [[ $(restart_count) > 0 ]] && [[ -e dmtcp_restart_script.sh ]]; then
./dmtcp_restart_script.sh &
else
echo "Failed to restart the job, exit"; exit
fi
# requeueing the job if remaining time >0
ckpt_command=ckpt_dmtcp #additional checkpointing right before the job hits the walllimit
requeue_job func_trap USR1
wait
This job script combines the two C/R job scripts in the previous section, run_launch.slurm and run_restart.slurm by checking the restart count of the job (if block). As before, the --time-min is used to split a long running job into multiple shorter ones to improve backfill opportunities. Each job will run with a time limit anywhere between the specified --time-min and time limit (-t), checkpointing once every hour (-i 3600).
What's new in this script is that
-
It can automatically track the remaining walltime, and resubmit itself until the job completes or the accumulated run time reaches the desired walltime (48 hours in this example).
-
Optionally, each job checkpoints one more time 300 seconds before the job hits the allocated time limit.
-
There is only one job id, and one standard output/error file associated with multiple shorter jobs.
These features are enabled with the following additional sbatch flags and a bash function rqueue_job, which traps the signal (USR1) sent from the batch system:
#SBATCH --comment=48:00:00 #comment for the job
#SBATCH --signal=B:USR1@<sig_time>
#SBATCH --requeue #specify job is requeueable
#SBATCH --open-mode=append #to append standard out/err of the requeued job
#to that of the previously terminated job
#requeueing the job if remaining time >0
ckpt_command=ckpt_dmtcp
requeue_job func_trap USR1
wait
where the --comment sbatch flag is used to specify the desired walltime and to track the remaining walltime for the job (after pre-termination). You can specify any length of time, e.g., a week or even longer. The --signal flag is used to request that the batch system sends user-defined signal USR1 to the batch shell (where the job is running) sig_time seconds (e.g., 300) before the job hits the wall limit. This time should match the checkpoint overhead of your job.
Upon receiving the signal USR1 from the batch system 300 seconds before the job hits the wall limit, the requeue_job executes the following commands (contained in a function func_trap provided on the requeue_job command line in the job script):
dmtcp_command --checkpoint #checkpoint the job if ckpt_command=ckpt_dmtcp
scontrol requeue $SLURM_JOB_ID #requeue the job
If your job completes before the job hits the wall limit, then the batch system will not send the USR1 signal, and the two commands above will not be executed (no additional checkpointing and no more requeued job). The job will exit normally.
For more details about the requeue_job and other functions used in the C/R job scripts, refer to the script cr_functions.sh provided by the nersc_cr module. (type module show nersc_cr to see where the script resides). You may consider making a local copy of this script, and modifying it for your use case.
To run the job, simply submit the job script,
sbatch run_cr.slurm
Note
-
It is important to make the
dmtcp_launchanddmtcp_restart_script.shrun in the background (&), and add a wait command at the end of the job script, so that when the batch system sends the USR1 signal to the batch shell, the wait command gets killed, instead of thedmtcp_launchordmtcp_restart_script.shcommands, so that they can continue to run to complete the last checkpointing right before the job hits the wall limit. -
You need to make the
sig_timein the--signalsbatch flag match the checkpoint overhead of your job. -
You may want to change the checkpoint interval for your job, especially if your job's checkpoint overhead is high. You can checkpoint only once before your job hits the wall limit.
-
Note that the
nersc_crmodule does not support csh. Csh/tcsh users must invoke bash before loading the module.
C/R MPI Applications with MANA¶
NERSC recommends MANA for checkpointing/restarting MPI applications on Cori, which works with any MPI implementation and network, including Cray MPICH over the Aries Network. MANA is implemented as a plugin in DMTCP, and users the dmtcp_coordinator, dmtcp_launch, dmtcp_restart, and dmtcp_command as described above, but with additional command line options. See the MANA page for checkpointing/restarting MPI applications.
DMTCP Help Pages¶
dmtcp_coordinator help page
cori$ dmtcp_coordinator --help
Usage: dmtcp_coordinator [OPTIONS] [port]
Coordinates checkpoints between multiple processes.
Options:
-p, --coord-port PORT_NUM (environment variable DMTCP_COORD_PORT)
Port to listen on (default: 7779)
--port-file filename
File to write listener port number.
(Useful with '--port 0', which is used to assign a random port)
--ckptdir (environment variable DMTCP_CHECKPOINT_DIR):
Directory to store dmtcp_restart_script.sh (default: ./)
--tmpdir (environment variable DMTCP_TMPDIR):
Directory to store temporary files (default: env var TMDPIR or /tmp)
--exit-on-last
Exit automatically when last client disconnects
--exit-after-ckpt
Kill peer processes of computation after first checkpoint is created
--daemon
Run silently in the background after detaching from the parent process.
-i, --interval (environment variable DMTCP_CHECKPOINT_INTERVAL):
Time in seconds between automatic checkpoints
(default: 0, disabled)
--coord-logfile PATH (environment variable DMTCP_COORD_LOG_FILENAME
Coordinator will dump its logs to the given file
-q, --quiet
Skip startup msg; Skip NOTE msgs; if given twice, also skip WARNINGs
--help:
Print this message and exit.
--version:
Print version information and exit.
COMMANDS:
type '?<return>' at runtime for list
Report bugs to: dmtcp-forum@lists.sourceforge.net
DMTCP home page: <http://dmtcp.sourceforge.net>
dmtcp_launch help page
cori$ dmtcp_launch --help
Usage: dmtcp_launch [OPTIONS] <command> [args...]
Start a process under DMTCP control.
Connecting to the DMTCP Coordinator:
-h, --coord-host HOSTNAME (environment variable DMTCP_COORD_HOST)
Hostname where dmtcp_coordinator is run (default: localhost)
-p, --coord-port PORT_NUM (environment variable DMTCP_COORD_PORT)
Port where dmtcp_coordinator is run (default: 7779)
--port-file FILENAME
File to write listener port number. (Useful with
'--coord-port 0', which is used to assign a random port)
-j, --join-coordinator
Join an existing coordinator, raise error if one doesn't
already exist
--new-coordinator
Create a new coordinator at the given port. Fail if one
already exists on the given port. The port can be specified
with --coord-port, or with environment variable
DMTCP_COORD_PORT.
If no port is specified, start coordinator at a random port
(same as specifying port '0').
--any-coordinator
Use --join-coordinator if possible, but only if port was specified.
Else use --new-coordinator with specified port (if avail.),
and otherwise with the default port: --port 7779)
(This is the default.)
--no-coordinator
Execute the process in standalone coordinator-less mode.
Use dmtcp_command or --interval to request checkpoints.
Note that this is incompatible with calls to fork(), since
an embedded coordinator runs in the original process only.
-i, --interval SECONDS (environment variable DMTCP_CHECKPOINT_INTERVAL)
Time in seconds between automatic checkpoints.
0 implies never (manual ckpt only);
if not set and no env var, use default value set in
dmtcp_coordinator or dmtcp_command.
Not allowed if --join-coordinator is specified
Checkpoint image generation:
--gzip, --no-gzip, (environment variable DMTCP_GZIP=[01])
Enable/disable compression of checkpoint images (default: 1)
WARNING: gzip adds seconds. Without gzip, ckpt is often < 1s
--ckptdir PATH (environment variable DMTCP_CHECKPOINT_DIR)
Directory to store checkpoint images
(default: curr dir at launch)
--ckpt-open-files
--checkpoint-open-files
Checkpoint open files and restore old working dir.
(default: do neither)
--allow-file-overwrite
If used with --checkpoint-open-files, allows a saved file
to overwrite its existing copy at original location
(default: file overwrites are not allowed)
--ckpt-signal signum
Signal number used internally by DMTCP for checkpointing
(default: SIGUSR2/12).
Enable/disable plugins:
--with-plugin (environment variable DMTCP_PLUGIN)
Colon-separated list of DMTCP plugins to be preloaded with
DMTCP.
(Absolute pathnames are required.)
--batch-queue, --rm
Enable support for resource managers (Torque PBS and SLURM).
(default: disabled)
--ptrace
Enable support for PTRACE system call for gdb/strace etc.
(default: disabled)
--modify-env
Update environment variables based on the environment on the
restart host (e.g., DISPLAY=$DISPLAY).
This can be set in a file dmtcp_env.txt.
(default: disabled)
--pathvirt
Update file pathnames based on DMTCP_PATH_PREFIX
(default: disabled)
--ib, --infiniband
Enable InfiniBand plugin. (default: disabled)
--disable-alloc-plugin: (environment variable DMTCP_ALLOC_PLUGIN=[01])
Disable alloc plugin (default: enabled).
--disable-dl-plugin: (environment variable DMTCP_DL_PLUGIN=[01])
Disable dl plugin (default: enabled).
--disable-all-plugins (EXPERTS ONLY, FOR DEBUGGING)
Disable all plugins.
--spades Enable support for spades.py
(-o <output-dir> spades.py option is required)
(default: disabled).
Other options:
--tmpdir PATH (environment variable DMTCP_TMPDIR)
Directory to store temp files (default: $TMDPIR or /tmp)
(Behavior is undefined if two launched processes specify
different tmpdirs.)
-q, --quiet (or set environment variable DMTCP_QUIET = 0, 1, or 2)
Skip NOTE messages; if given twice, also skip WARNINGs
--coord-logfile PATH (environment variable DMTCP_COORD_LOG_FILENAME
Coordinator will dump its logs to the given file
--help
Print this message and exit.
--version
Print version information and exit.
Report bugs to: dmtcp-forum@lists.sourceforge.net
DMTCP home page: <http://dmtcp.sourceforge.net>
dmtcp_restart help page
cori$ dmtcp_restart --help
Usage: dmtcp_restart [OPTIONS] <ckpt1.dmtcp> [ckpt2.dmtcp...]
Restart processes from a checkpoint image.
Connecting to the DMTCP Coordinator:
-h, --coord-host HOSTNAME (environment variable DMTCP_COORD_HOST)
Hostname where dmtcp_coordinator is run (default: localhost)
-p, --coord-port PORT_NUM (environment variable DMTCP_COORD_PORT)
Port where dmtcp_coordinator is run (default: 7779)
--port-file FILENAME
File to write listener port number.
(Useful with '--port 0', in order to assign a random port)
-j, --join-coordinator
Join an existing coordinator, raise error if one doesn't
already exist
--new-coordinator
Create a new coordinator at the given port. Fail if one
already exists on the given port. The port can be specified
with --coord-port, or with environment variable
DMTCP_COORD_PORT.
If no port is specified, start coordinator at a random port
(same as specifying port '0').
--any-coordinator
Use --join-coordinator if possible, but only if port was specified.
Else use --new-coordinator with specified port (if avail.),
and otherwise with the default port: --port 7779)
(This is the default.)
-i, --interval SECONDS (environment variable DMTCP_CHECKPOINT_INTERVAL)
Time in seconds between automatic checkpoints.
0 implies never (manual ckpt only); if not set and no env
var, use default value set in dmtcp_coordinator or
dmtcp_command.
Not allowed if --join-coordinator is specified
Other options:
--no-strict-checking
Disable uid checking for checkpoint image. Allow checkpoint
image to be restarted by a different user than the one
that created it. And suppress warning about running as root.
(environment variable DMTCP_DISABLE_STRICT_CHECKING)
--ckptdir (environment variable DMTCP_CHECKPOINT_DIR):
Directory to store checkpoint images
(default: use the same dir used in previous checkpoint)
--tmpdir PATH (environment variable DMTCP_TMPDIR)
Directory to store temp files (default: $TMDPIR or /tmp)
-q, --quiet (or set environment variable DMTCP_QUIET = 0, 1, or 2)
Skip NOTE messages; if given twice, also skip WARNINGs
--coord-logfile PATH (environment variable DMTCP_COORD_LOG_FILENAME
Coordinator will dump its logs to the given file
--debug-restart-pause (or set env. var. DMTCP_RESTART_PAUSE =1,2,3 or 4)
dmtcp_restart will pause early to debug with: GDB attach
--help
Print this message and exit.
--version
Print version information and exit.
Report bugs to: dmtcp-forum@lists.sourceforge.net
DMTCP home page: <http://dmtcp.sourceforge.net>
dmtcp_command help page
cori$ dmtcp_command --help
Usage: dmtcp_command [OPTIONS] COMMAND [COMMAND...]
Send a command to the dmtcp_coordinator remotely.
Options:
-h, --coord-host HOSTNAME (environment variable DMTCP_COORD_HOST)
Hostname where dmtcp_coordinator is run (default: localhost)
-p, --coord-port PORT_NUM (environment variable DMTCP_COORD_PORT)
Port where dmtcp_coordinator is run (default: 7779)
--help
Print this message and exit.
--version
Print version information and exit.
Commands for Coordinator:
-s, --status: Print status message
-l, --list: List connected clients
-c, --checkpoint: Checkpoint all nodes
-bc, --bcheckpoint: Checkpoint all nodes, blocking until done
-i, --interval <val> Update ckpt interval to <val> seconds (0=never)
-k, --kill Kill all nodes
-q, --quit Kill all nodes and quit
Report bugs to: dmtcp-forum@lists.sourceforge.net
DMTCP home page: <http://dmtcp.sourceforge.net>
Resources¶
- DMTCP website
- DMTCP github
- DMTCP user training slides (Nov. 2019)
- dmtcp modules on Cori used https://github.com/JainTwinkle/dmtcp.git (branch: spades-v2)
- MANA for MPI: MPI-Agnostic Network-Agnostic Transparent Checkpointing