Sky surveys are the largest data generators in astronomy, making automated tools for extracting meaningful scientific information an absolute necessity. We have shown that, without the need for labels, self-supervised learning generates representations of sky survey images that are semantically useful for a variety of scientific tasks. These representations can be directly used as features, or fine-tuned, to outperform supervised methods trained only on labeled data in tasks like morphology classification or redshift estimation. Our efforts so far have demonstrated the power of self-supervised learning using multi-band galaxy photometry from the Sloan Digital Sky Survey (SDSS) as a testbed. On this webpage, you can find an overview of our paper, and the code and data used in the project. We aim to update this page as the project progresses, so please stay tuned.
SDSS Dataset and Associated Labels
Here you can read about our dataset of SDSS images, along with the morphology and redshift labels used for supervised tasks. We are still in the process of releasing all datasets used, but some is available now for download.
Pretrained Models
Here you can find some pretrained models for networks in our SDSS paper. There are self-supervised models which generate representations for use in downstream tasks and analysis, and we also include the supervised baseline networks from the paper.
Paper Overview: Self-Supervised Representation Learning for Astronomical Images
Link to paper: arxiv preprint
Link to code: github repository
Method
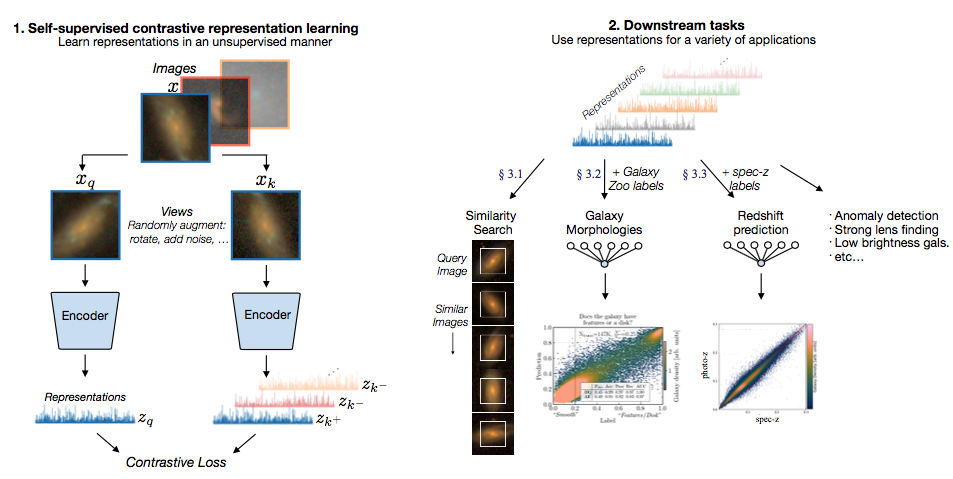
To get good image representations, we train an encoder neural network using different augmented views of SDSS galaxy images using a contrastive learning framework. To produce our augmented views, we randomly apply rotation, slight jittering of the image center, additive gaussian noise, and artificial galactic extinction to the images. The encoder network is trained via a contrastive loss function, which maximizes the similarity of the encoder's representations for different augmented views of the same image, while minimizing the similarity of representations of other images. Then, the learned representations (simply a lower dimensional vector encoding of the image) can be used for downstream analysis tasks.
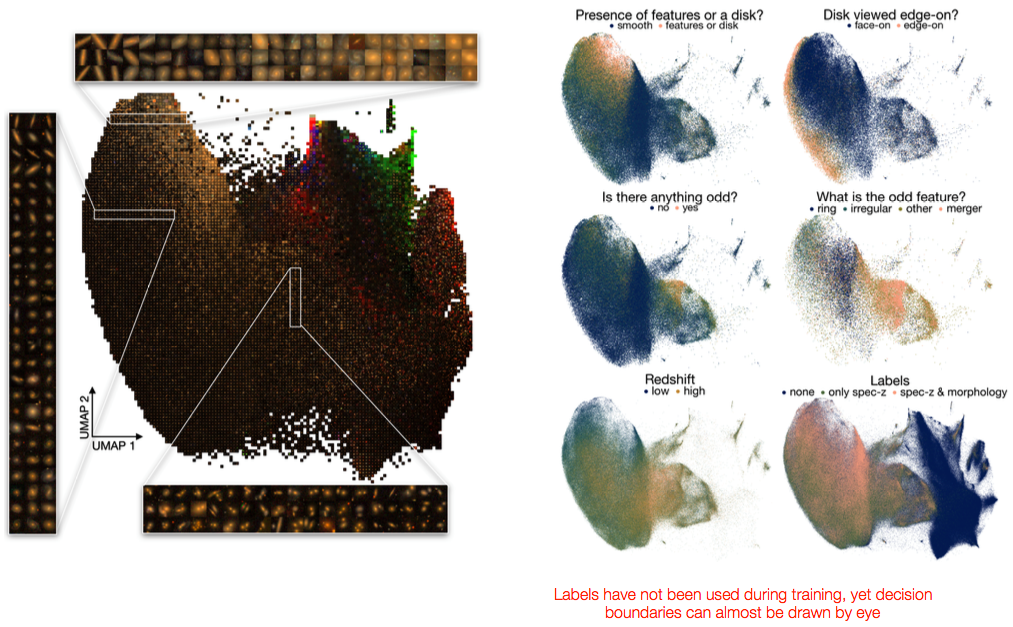
Representations of SDSS galaxies
After self-supervsied pre-training, our encoder yields a meaningful representation of each image. To visualize the representation space, we can apply some dimensionality reduction (UMAP) and plot where different types of galaxies show up in the reduced space (a two-dimensional plane). We see distinct clustering according to galaxy morphological characteristics and redshifts.
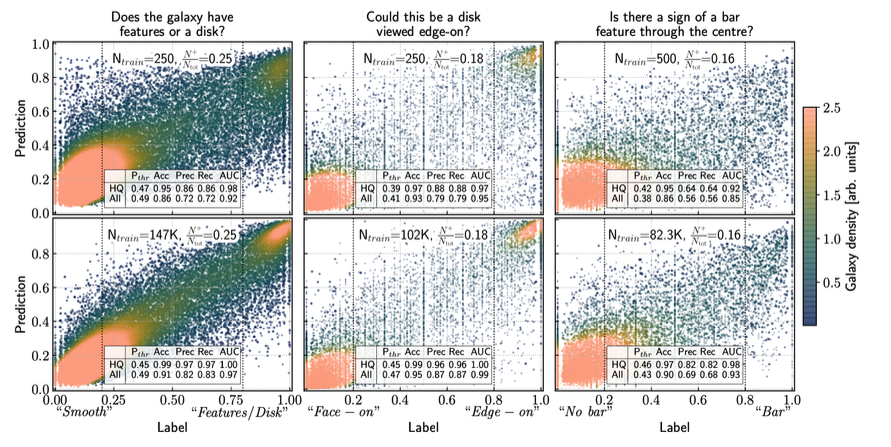
Downstream Tasks
The self-supervised representations contain information that is immediately useful for downstream tasks. For example, using morphology labels from the Galaxy Zoo 2 project, we can train a linear classifier directly on the representations to predict morpgological characteristics of each galaxy to a remarkable degree of accuracy. This classifer is accurate even under highly limited training data, and takes 0.5-10 seconds to train on a single GPU.
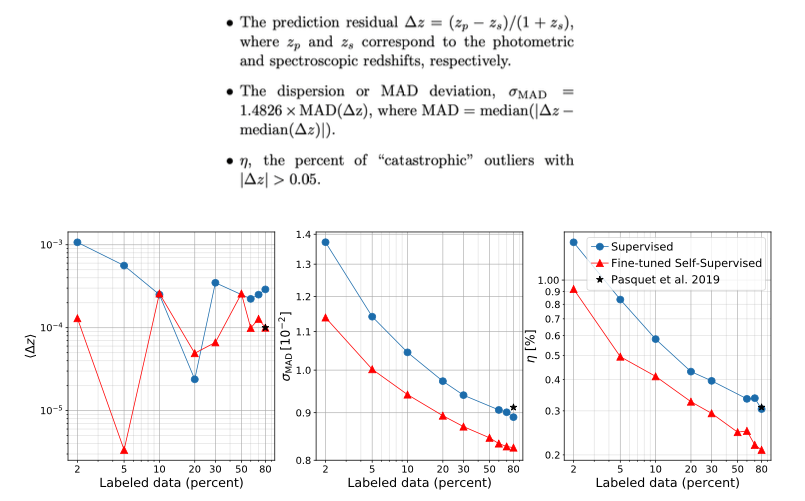
Another relevant task is predicting the redshift of a galaxy (photometric redshift estimation), for which we use spectroscopic redhisft measurements to train the model. To solve this regression task, we train a linear classifier on the representations to predict the redshift "bin" of a given sample, while adjusting the weights of the convolutional encoder network with a 10x smaller learning rate. This fine-tuning process achieves significantly better redshift predictions, even when the training set size is tightly restricted, than a traditional fully-supervised approach. Using all of our spectroscopic labels, we achieve a new state of the art for image-based redshift estimation on this dataset according to the standard accuracy metrics. Notably, our fine-tuned self-supervised model can achieve the equivalent performance of a supervised model that uses 2-4x more training data.