Data Model
Contents
Data Model¶
TOAST works with data organized into observations. Each observation is independent of any other observation. An observation consists of co-sampled detectors for some span of time. The intrinsic detector noise is assumed to be stationary within an observation. Typically there are other quantities which are constant for an observation (e.g. elevation, weather conditions, satellite precession axis, etc).
A TOAST workflow consists of one or more (possibly distributed)
observations representing the data, and a series of operators that
work with this data (see the processing-model{.interpreted-text
role=”ref”} section).
Observations¶
The [Observation]{.title-ref} class is the mid-level data container in TOAST.
- class toast.Observation(comm, telescope, n_samples, name=None, uid=None, detector_sets=None, sample_sets=None, process_rows=None)¶
Class representing the data for one observation.
An Observation stores information about data distribution across one or more MPI processes and is a container for four types of objects:
Local detector data (unique to each process).
Shared data that has one common copy for every node spanned by the observation.
Intervals defining spans of data with some common characteristic.
Other arbitrary small metadata.
Small metadata can be stored directly in the Observation using normal square bracket “[]” access to elements (an Observation is a dictionary). Groups of detector data (e.g. “signal”, “flags”, etc) can be accessed in the separate detector data dictionary (the “detdata” attribute). Shared data can be similarly stored in the “shared” attribute. Lists of intervals are accessed in the “intervals” attribute and data views can use any interval list to access subsets of detector and shared data.
Notes on distributed use with MPI
The detector data within an Observation is distributed among the processes in an MPI communicator. The processes in the communicator are arranged in a rectangular grid, with each process storing some number of detectors for a piece of time covered by the observation. The most common configuration (and the default) is to make this grid the size of the communicator in the “detector direction” and a size of one in the “sample direction”:
MPI det1 sample(0), sample(1), sample(2), ...., sample(N-1) rank 0 det2 sample(0), sample(1), sample(2), ...., sample(N-1) ---------------------------------------------------------------------- MPI det3 sample(0), sample(1), sample(2), ...., sample(N-1) rank 1 det4 sample(0), sample(1), sample(2), ...., sample(N-1)
So each process has a subset of detectors for the whole span of the observation time. You can override this shape by setting the process_rows to something else. For example, process_rows=1 would result in this:
MPI rank 0 | MPI rank 1 ----------------------------------+---------------------------- det1 sample(0), sample(1), ..., | ...., sample(N-1) det2 sample(0), sample(1), ..., | ...., sample(N-1) det3 sample(0), sample(1), ..., | ...., sample(N-1) det4 sample(0), sample(1), ..., | ...., sample(N-1)
- Parameters
comm (toast.Comm) – The toast communicator containing information about the process group for this observation.
telescope (Telescope) – An instance of a Telescope object.
n_samples (int) – The total number of samples for this observation.
name (str) – (Optional) The observation name.
uid (int) – (Optional) The Unique ID for this observation. If not specified, the UID will be computed from a hash of the name.
detector_sets (list) – (Optional) List of lists containing detector names. These discrete detector sets are used to distribute detectors- a detector set will always be within a single row of the process grid. If None, every detector is a set of one.
sample_sets (list) – (Optional) List of lists of chunk sizes (integer numbers of samples). These discrete sample sets are used to distribute sample data. A sample set will always be within a single column of the process grid. If None, any distribution break in the sample direction will happen at an arbitrary place. The sum of all chunks must equal the total number of samples.
process_rows (int) – (Optional) The size of the rectangular process grid in the detector direction. This number must evenly divide into the size of comm. If not specified, defaults to the size of the communicator.
- clear() None. Remove all items from D.¶
- property telescope¶
The Telescope instance for this observation.
- Type
(Telescope)
- property name¶
The name of the observation.
- Type
(str)
- property uid¶
The Unique ID for this observation.
- Type
(int)
- property comm¶
The overall communicator.
- Type
- property comm_row¶
The communicator for processes in the same row (or None).
- Type
(mpi4py.MPI.Comm)
- property comm_row_size¶
The number of processes in the row communicator.
- Type
(int)
- property comm_row_rank¶
The rank of this process in the row communicator.
- Type
(int)
- property comm_col¶
The communicator for processes in the same column (or None).
- Type
(mpi4py.MPI.Comm)
- property comm_col_size¶
The number of processes in the column communicator.
- Type
(int)
- property comm_col_rank¶
The rank of this process in the column communicator.
- Type
(int)
- property all_detectors¶
All detectors stored in this observation.
- Type
(list)
- property local_detectors¶
The detectors assigned to this process.
- Type
(list)
- select_local_detectors(selection=None)¶
(list): The detectors assigned to this process, optionally pruned.
- property all_detector_sets¶
The total list of detector sets for this observation.
- Type
(list)
- property local_detector_sets¶
The detector sets assigned to this process (or None).
- Type
(list)
- property n_all_samples¶
the total number of samples in this observation.
- Type
(int)
- property local_index_offset¶
The first sample on this process, relative to the observation start.
- property n_local_samples¶
The number of local samples on this process.
- property all_sample_sets¶
The input full list of sample sets used in data distribution
- Type
(list)
- property local_sample_sets¶
The sample sets assigned to this process (or None).
- Type
(list)
- duplicate(times=None, meta=None, shared=None, detdata=None, intervals=None)¶
Return a copy of the observation and all its data.
The times field should be the name of the shared field containing timestamps. This is used when copying interval lists to the new observation so that these objects reference the timestamps within this observation (rather than the old one). If this is not specified and some intervals exist, then an exception is raised.
The meta, shared, detdata, and intervals list specifies which of those objects to copy to the new observation. If these are None, then all objects are duplicated.
- Parameters
times (str) – The name of the timestamps shared field.
meta (list) – List of metadata objects to copy, or None.
shared (list) – List of shared objects to copy, or None.
detdata (list) – List of detdata objects to copy, or None.
intervals (list) – List of intervals objects to copy, or None.
- Returns
The new copy of the observation.
- Return type
- memory_use()¶
Estimate the memory used by shared and detector data.
This sums the memory used by the shared and detdata attributes and returns the total on all processes. This function is blocking on the observation communicator.
- Returns
The number of bytes of memory used by timestream data.
- Return type
(int)
- redistribute(process_rows, times=None, override_sample_sets=False, override_detector_sets=False)¶
Take the currently allocated observation and redistribute in place.
This changes the data distribution within the observation. After re-assigning all detectors and samples, the currently allocated shared data objects and detector data objects are redistributed using the observation communicator.
- Parameters
process_rows (int) – The size of the new process grid in the detector direction. This number must evenly divide into the size of the observation communicator.
times (str) – The shared data field representing the timestamps. This is used to recompute the intervals after redistribution.
override_sample_sets (False, None or list) – If not False, override existing sample set boundaries in the redistributed data.
override_detector_sets (False, None or list) – If not False, override existing detector set boundaries in the redistributed data.
- Returns
None
- acc_copyin(names)¶
Copy a set of data objects to the device.
This takes a dictionary with the same format as those used by the Operator provides() and requires() methods.
- Parameters
names (dict) – Dictionary of lists.
- Returns
None
- acc_copyout(names)¶
Copy a set of data objects to the host.
This takes a dictionary with the same format as those used by the Operator provides() and requires() methods.
- Parameters
names (dict) – Dictionary of lists.
- Returns
None
The following sections detail the classes that represent TOAST data sets and how that data can be distributed among many MPI processes.
Instrument Model¶
focalplane
pointing rotation
detector and beam orientation
Noise Model¶
Each observation can also have a noise model associated with it. An instance of a Noise class (or derived class) describes the noise properties for all detectors in the observation.
Intervals¶
Within each TOD object, a process contains some local set of detectors and range of samples. That range of samples may contain one or more contiguous “chunks” that were used when distributing the data. Separate from this data distribution, TOAST has the concept of valid data “intervals”. This list of intervals applies to the whole observation, and all processes have a copy of this list. This list of intervals is useful to define larger sections of data than what can be specified with per-sample flags. A single interval looks like this:
The Data Class¶
The data used by a TOAST workflow consists of a list of observations, and is encapsulated by the [toast.Data]{.title-ref} class.
If you are running with a single process, that process has all observations and all data within each observation locally available. If you are running with more than one process, the data with be distributed across processes.
Distribution¶
Although you can use TOAST without MPI, the package is designed for data that is distributed across many processes. When passing the data through a toast workflow, the data is divided up among processes based on the details of the [toast.Comm]{.title-ref} class that is used and also the shape of the process grid in each observation.
A toast.Comm instance takes the global number of processes available (MPI.COMM_WORLD) and divides them into groups. Each process group is assigned one or more observations. Since observations are independent, this means that different groups can be independently working on separate observations in parallel. It also means that inter-process communication needed when working on a single observation can occur with a smaller set of processes.
- class toast.Comm(world=None, groupsize=0)¶
Class which represents a two-level hierarchy of MPI communicators.
A Comm object splits the full set of processes into groups of size “group”. If group_size does not divide evenly into the size of the given communicator, then those processes remain idle.
A Comm object stores several MPI communicators: The “world” communicator given here, which contains all processes to consider, a “group” communicator (one per group), and a “rank” communicator which contains the processes with the same group-rank across all groups.
This object also stores a “node” communicator containing all processes with access to the same shared memory, and a “node rank” communicator for processes with the same rank on a node. There is a node rank communicator for all nodes and also one for within the group.
Additionally, there is a mechanism for creating and caching row / column communicators for process grids within a group.
If MPI is not enabled, then all communicators are set to None. Additionally, there may be cases where MPI is enabled in the environment, but the user wishes to disable it when creating a Comm object. This can be done by passing MPI.COMM_SELF as the world communicator.
- Parameters
world (mpi4py.MPI.Comm) – the MPI communicator containing all processes.
group (int) – the size of each process group.
- property world_size¶
The size of the world communicator.
- property world_rank¶
The rank of this process in the world communicator.
- property ngroups¶
The number of process groups.
- property group¶
The group containing this process.
- property group_size¶
The size of the group containing this process.
- property group_rank¶
The rank of this process in the group communicator.
- property comm_world¶
The world communicator.
- property comm_world_node¶
The communicator shared by world processes on the same node.
- property comm_world_node_rank¶
The communicator shared by world processes with the same node rank across all nodes.
- property comm_group¶
The communicator shared by processes within this group.
- property comm_group_rank¶
The communicator shared by processes with the same group_rank.
- property comm_group_node¶
The communicator shared by group processes on the same node.
- property comm_group_node_rank¶
The communicator shared by group processes with the same node rank on nodes within the group.
- comm_row_col(process_rows)¶
Return the row and column communicators for this group and grid shape.
This function will create and / or return the communicators needed for a given process grid. The return value is a dictionary with the following keys:
“row”: The row communicator.
“col”: The column communicator.
“row_node”: The node-local communicator within the row communicator
“col_node”: The node-local communicator within the col communicator
- “row_rank_node”: The communicator across nodes among processes with
the same node-rank within the row communicator.
- “col_rank_node”: The communicator across nodes among processes with
the same node-rank within the column communicator.
- Parameters
process_rows (int) – The number of rows in the process grid.
- Returns
The communicators for this grid shape.
- Return type
(dict)
Just to reiterate, if your [toast.Comm]{.title-ref} has multiple process groups, then each group will have an independent list of observations in [toast.Data.obs]{.title-ref}.
What about the data within an observation? A single observation is owned by exactly one of the process groups. The MPI communicator passed to the TOD constructor is the group communicator. Every process in the group will store some piece of the observation data. The division of data within an observation is controlled by the [detranks]{.title-ref} option to the TOD constructor. This option defines the dimension of the rectangular “process grid” along the detector (as opposed to time) direction. Common values of [detranks]{.title-ref} are:
“1” (processes in the group have all detectors for some slice of time)
Size of the group communicator (processes in the group have some of the detectors for the whole time range of the observation)
The detranks parameter must divide evenly into the number of processes in the group communicator.
Examples¶
It is useful to walk through the process of how data is distributed for a simple case. We have some number of observations in our data, and we also have some number of MPI processes in our world communicator:
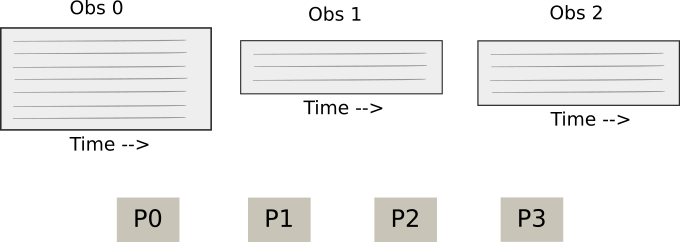
Starting point: Observations and MPI Processes.
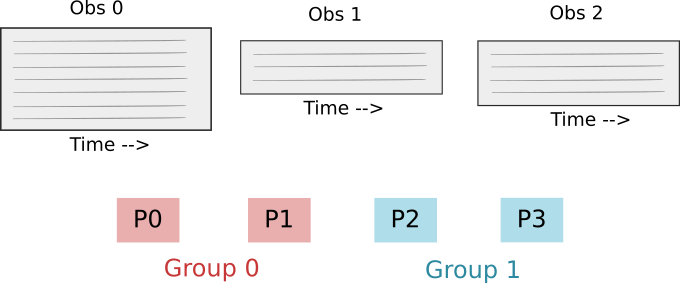
Defining the process groups: We divide the total processes into equal-sized groups.
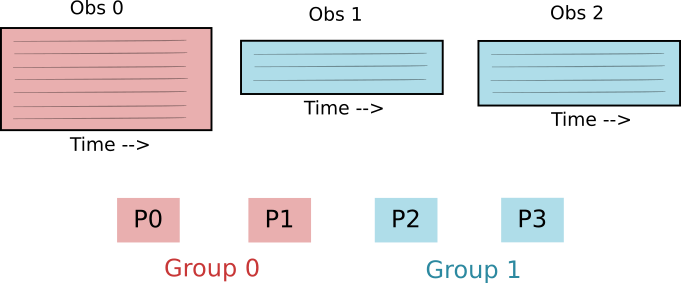
Assign observations to groups: Each observation is assigned to exactly one group. Each group has one or more observations.
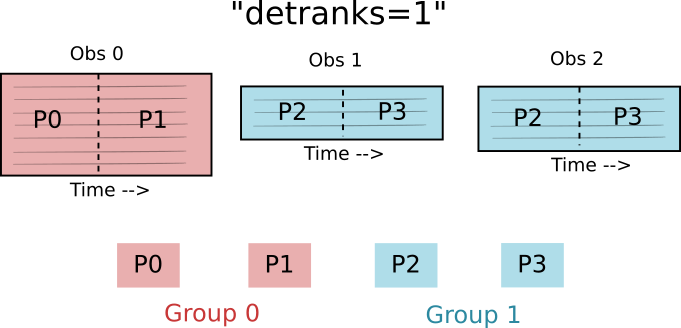
The [detranks]{.title-ref} TOD constructor argument specifies how data within an observation is distributed among the processes in the group. The value sets the dimension of the process grid in the detector direction. In the above case, [detranks = 1]{.title-ref}, so the process group is arranged in a one-dimensional grid in the time direction.
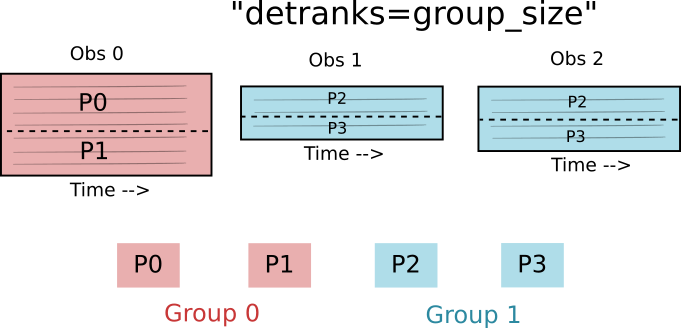
In the above case, the [detranks]{.title-ref} parameter is set to the size of the group. This means that the process group is arranged in a one-dimensional grid in the process direction.
Now imagine a more complicated case (not currently used often if at all) where the process group is arranged in a two-dimensional grid. This is useful as a visualization exercise. Let’s say that MPI.COMM_WORLD has 24 processes. We split this into 4 groups of 6 procesess. There are 6 observations of varying lengths and every group has one or 2 observations. For this case, we are going to use [detranks = 2]{.title-ref}. Here is a picture of what data each process would have. The global process number is shown as well as the rank within the group:
